Something happened this week that I keep turning over.
MIT published findings this month showing that when 41 AI models were tested across more than 11,000 real workplace tasks, the result was, in their words, like a “disenchanted intern” — hitting minimum benchmarks about 65% of the time, but never exceeding 50% success on tasks requiring genuinely superior-quality output. If you work in software, marketing, legal services, or knowledge work of any kind, that’s the snapshot.
METR — a nonprofit focused on measuring AI capabilities — published a different kind of snapshot. Their metric is the “time horizon”: the maximum length of autonomous task a frontier AI can reliably complete. In 2019, the best AI could handle roughly a two-minute task without human intervention. By the end of 2025, that had grown to roughly an hour. The doubling time across that whole period: around seven months.
METR’s January 2026 update tightened that number further. Post-2023, the best estimate for the doubling period is now 130 days — closer to four months.
My read on this:
The MIT study and the METR data aren’t in conflict. They’re measuring different things at different timescales. MIT is taking a photograph. METR is measuring the shutter speed. And the shutter speed is getting faster.
I don’t think the “disenchanted intern” framing is wrong — it describes today accurately. What I’m less sure about is the assumption, implicit in most of the coverage I’ve read this week, that “today” is a stable state. An intern who gets twice as capable every four months is not the same resource at the end of the year as they are today.
What I keep returning to is the gap between the current snapshot and the trajectory — and the opportunity that opens up in that gap. The MIT data is a photograph of now. The METR data is the shutter speed. Anyone building workflows, designing teams, or structuring how they work around AI capability today is working from a reference point that will be measurably out of date within a single planning cycle. That’s an opportunity signal at a scale and pace most planning assumptions don’t account for.
Three things I’m watching:
1. Where the doubling curve hits friction. Every exponential eventually meets a wall — physical limits, data constraints, regulatory friction. METR’s time-horizon metric is useful precisely because it measures real-world task completion, not synthetic benchmark scores. When the doubling cadence breaks, that will be the signal that the curve has met something real. I expect that to happen. I just don’t know when.
2. Whether “minimally sufficient” matters or not. MIT’s 65% minimally sufficient rate sounds modest. But most enterprise workflows run on people who are minimally sufficient most of the time. The threshold isn’t excellence — it’s “acceptable at scale, around the clock, at near-zero marginal cost.” That bar is lower than it sounds, and closer than the headline number implies.
3. The infrastructure spend as an access unlock. Alphabet, Meta, Microsoft, and Amazon are projected to spend nearly $700 billion combined on AI infrastructure in 2026 — roughly double what they spent last year. That capital isn’t just building capacity for the current snapshot. It’s funding the cost compression that makes the next several capability doublings broadly accessible. When the infrastructure matures, the cost floor drops — and the surface area for building on top of it expands with it.
The disenchanted intern framing is apt today. My expectation is that it’s a better description of 2025 than it is of 2027.
Every knowledge worker is a manager now. Agentic AI has turned individual contributors into managers of AI agents, and first-line managers into leaders of managers of agents. The job descriptions have not caught up yet. The operating models have not caught up yet. The reskilling plans have not caught up yet. All of that is lagging the capability frontier by twelve to eighteen months — and the organizations that close that gap first will operate at a structurally different throughput than the ones still writing job descriptions for the jobs that existed in 2023.
The shift: agentic AI crosses the line from tool to colleague
For the first year and a half after ChatGPT, the thing called “AI” in most organizations was a better search box. A more patient editor. A faster rough-draft generator. Useful, but still a single-interaction tool. You asked, it answered, you moved on. The job of the knowledge worker did not fundamentally change — they just had a slightly sharper pencil.
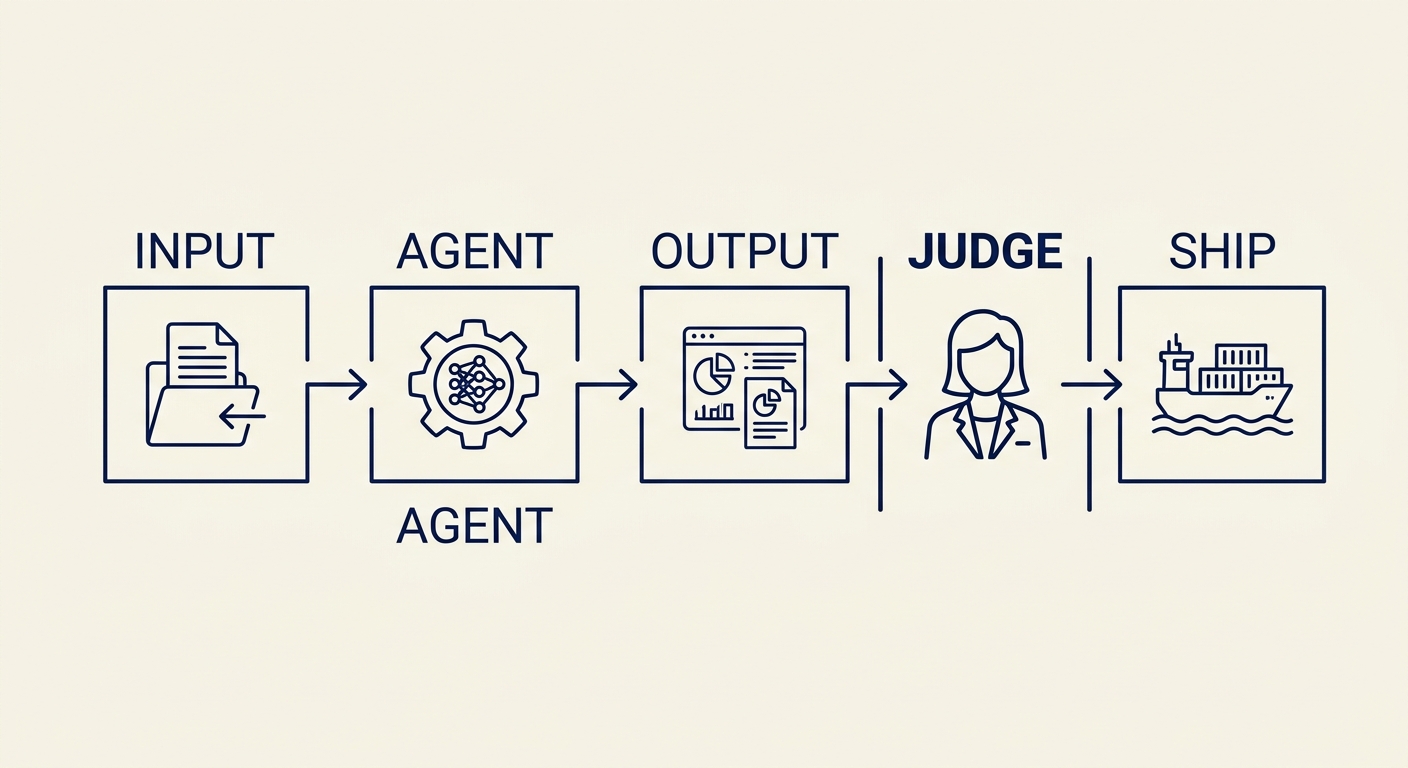
What changed in the eighteen months leading into 2026 is the arrival of agentic models. The word “agent” in that context is not marketing. An agent is a system that can do a sequence of things, hold state across those steps, make decisions about what to do next, use tools, and come back with a completed multi-step task. That is a categorically different interaction than “ask question, get answer.” It is closer to “give a junior colleague an outcome to produce and trust them to produce it.” The commercial consequence of that shift is the subject of this post.
Input → agent → output → judge → ship. The human stays at the judgment node.
The role change: ICs become managers of agents
The individual contributor job has silently changed. Writing short summaries of long content — once a junior-to-mid task — is now an agent task. The human role is to specify the outcome, check the output, and decide what to do with it. Meeting preparation — the pre-meeting brief of background, context, attendees, prior touchpoints — is now an agent task. The human role is to feed the context, review the brief, and adjust the framing. Drafting a first pass of almost any structured document — a proposal, a plan, an analysis — is now an agent task. The human role is the editor, not the author of the first draft.
The common thread is that the IC’s job has shifted from doing to specifying outcomes and judging output. Those are management skills. Not in the metaphorical sense — in the literal sense. Framing a task clearly enough that someone (or something) else can execute it. Evaluating whether the execution meets the specification. Deciding when to iterate and when to ship. These are exactly the skills that used to distinguish a first-line manager from a senior IC, and they have become baseline requirements for an IC working with agents.
The new role for the IC: editor of agent output.
The org change: first-line managers become leaders of managers of agents
If every IC is now a manager of agents, then every first-line manager is now a leader of managers of agents. Their job is no longer to supervise execution — the agent is doing the execution. Their job is to coach the humans on their team in how to specify outcomes, how to judge output, how to know when an agent is producing garbage, and how to scale their orchestration over time. That is a completely different job than the first-line management job of three years ago, and it requires a different skill set.
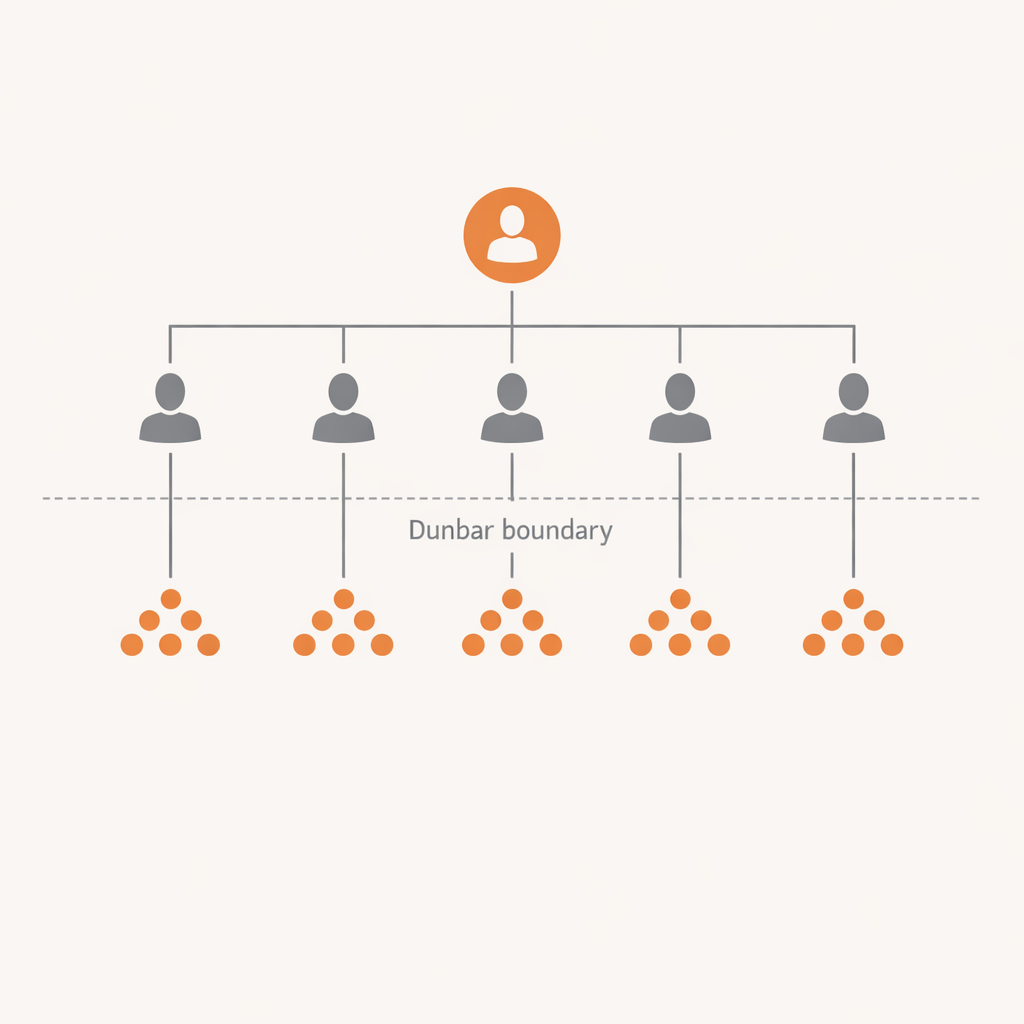
Two structural consequences follow. First, the middle management layer compresses because a first-line manager leading managers-of-agents can reach further than one managing direct executors — the coordination overhead per report drops when the reports are themselves operating on a multiplier. Second, the definition of “span of control” stretches, but not infinitely: the Dunbar layers still govern the number of humans a manager can hold relationships with, even if each of those humans is now operating agents underneath them. The org chart can get flatter. It cannot get unbounded.
One human, many agents — the conductor metaphor for first-line management at scale.
The strategic consequence: orchestration is now a baseline skill, not an advanced one
The skill that used to distinguish senior managers from junior ones — the ability to frame work so someone else can execute it and judge whether their execution is good — is now a baseline IC capability. Orchestration is the new baseline. Writing is the new baseline. Judgment about output quality is the new baseline. The organizations that will operate at structurally higher throughput over the next five years are the ones that reskill their IC population around these baseline orchestration skills, rather than hiring more specialists who each do one thing well.
Talent leverage, not headcount, becomes the scoreboard. A commercial organization that operates at 300 humans with strong orchestration capability can outproduce a commercial organization that operates at 600 humans with legacy IC job descriptions. The difference is not about working harder. It is about operating model. The 300-human organization has fewer Dunbar breakpoints, shorter decision loops, less cross-functional friction, and a higher per-seat agent-multiplier. All of that is the consequence of a single structural decision made at the job-description layer.
So what boards should do
Three actions sit on the CEO agenda over the next two quarters. First, rewrite the IC job descriptions for every knowledge-worker role in the organization so that orchestration and output judgment are explicit baseline capabilities, not bonus ones. Second, rewrite the first-line management job description so that coaching for orchestration is the core of the role, not supervision of execution. Third, audit the reskilling plan against the assumption that every knowledge worker in the organization is now a manager and needs to be trained as one — because the capability frontier has already shipped and the only question is whether the organization catches up in quarters or in years.
Boards that do not require a reskilling plan at this scope are budgeting against an operating model that does not exist anymore. The plan does not need to be perfect. It needs to exist. The gap between organizations that have this plan and organizations that do not is the structural competitive advantage of the next five years, and it is already being measured — in throughput, in decision velocity, in the quiet retention of the top performers who can see the gap coming.
Team sizes are not design choices. They are cognitive limits. The recurring numbers that show up in military units, religious communities, hunter-gatherer bands, and commercial organizations are not management philosophy. They are a property of the animal doing the work, and any organizational structure that pretends otherwise pays a measurable tax in friction, communication overhead, quiet attrition, and decisions that arrive three weeks late.
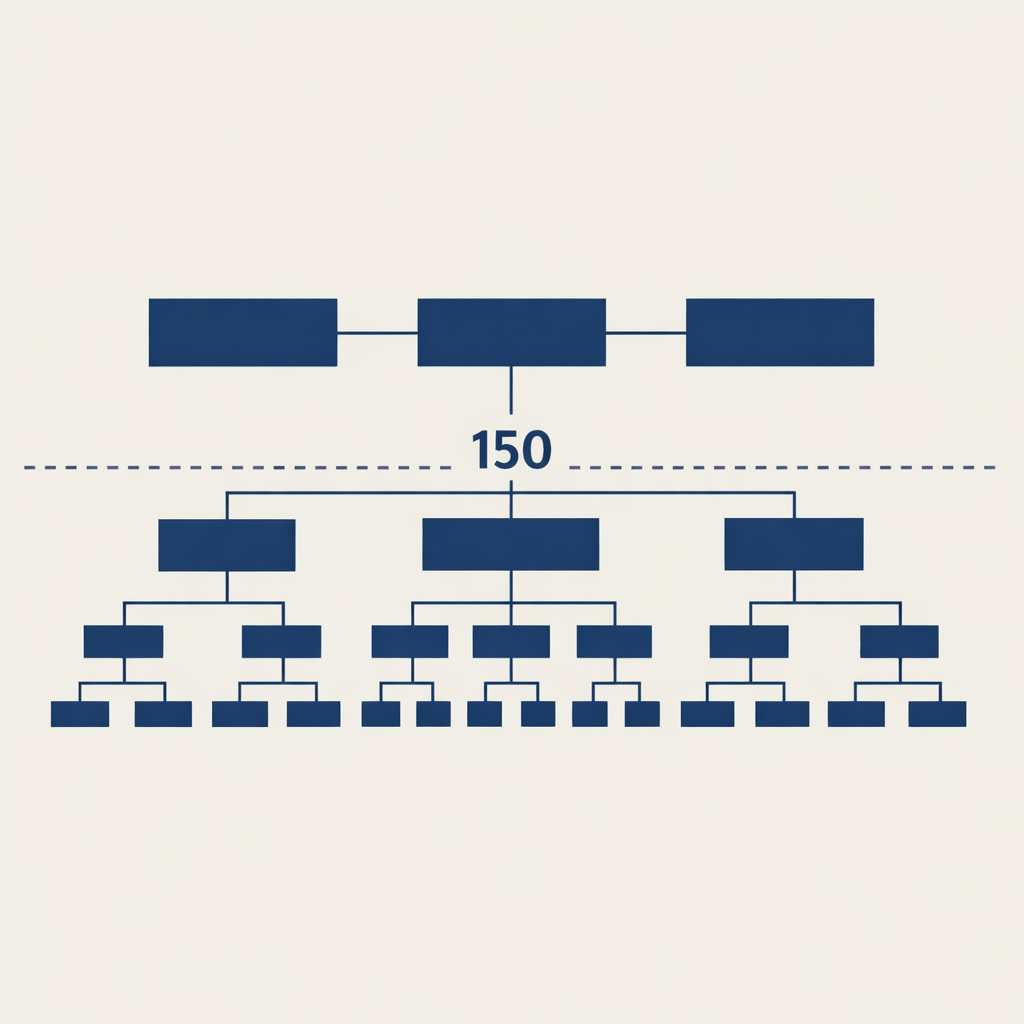
Two. Four to six. Eight to twelve. Twenty to twenty-five. Fifty. One hundred and fifty. The specific numbers recur across centuries and industries. In the Roman legion and the US Marines. In religious communities and hunter-gatherer bands. In tech companies, sales organizations, and the advice experienced managers give each other about when to split a growing team. It is not a coincidence. It is cognitive architecture. The constraint is no longer technology. The constraint has always been the brain doing the coordinating.
Dunbar’s layers
The research most commercial leaders eventually bump into is Robin Dunbar’s. Dunbar is a British anthropologist who, in the early 1990s, proposed that the size of a primate’s social group is constrained by the size of its neocortex. Extrapolating from primate data, he estimated the human number at around 150 — the number of people with whom any one of us can maintain a stable, recognisable, mutually-active relationship. He published it in the Journal of Human Evolution in 1992, and the number has been running through management literature ever since.
The part that gets talked about less, but matters more, is that Dunbar’s 150 is not a single flat layer. It is the outer ring of a nested set, each layer roughly three times larger than the one inside it:
~5 — your closest support group. The people you would call in a real emergency.
~15 — your sympathy group. People whose loss would significantly affect you.
~50 — your band or clan. People you know well enough to share deep context with.
~150 — your active community. Stable, recognisable, mutually reciprocal relationships.
~500 — acquaintances.
~1500 — faces you can still recognise.
These layers show up in the research almost regardless of whether the subject is a tribal society, an office workforce, or a social-network friend graph. And they map astonishingly well onto the team sizes that commercial organizations stumble toward by trial and error — not because anyone read Dunbar, but because the alternatives don’t work.
A central figure surrounded by expanding tiers — 5, 15, 50, 150.
The military got there first
Armies have been experimenting with how to organize humans under extreme stress for two thousand years, and they arrived at exactly these numbers through pure selection pressure. Smaller was too fragile. Larger fell apart under fire. The numbers that survived are the numbers that work.
A Roman legion’s smallest unit was the contubernium — eight soldiers who shared a tent, a mule, a mess, and most of their waking life. Eight. Right at the boundary between the 5-person inner layer and the 15-person sympathy group. The Romans knew nothing about neocortex ratios. They noticed that a group of eight held together in a way that a group of four or a group of sixteen did not.
The modern US Marine Corps fireteam is four. The squad is roughly 13. The platoon is 30 to 40. The company is 100 to 150. The same ratios, twenty-one centuries later. The cognitive limits haven’t moved, because the brain they are about hasn’t.
The tech industry rediscovered the same numbers
The technology industry discovered the same structure and gave it different names.
Jeff Bezos’s two-pizza rule — a team should be small enough to be fed by two pizzas — is a practical restatement of the 5-to-8 cognitive sub-layer. Amazon did not get there via anthropology. They got there by watching their own product teams stall every time they grew past the point where the whole group could fit around one table.
Scrum teams are officially 7 ± 2 — the current Scrum Guide recommends 3 to 9 members — which echoes George Miller’s 1956 paper on the working-memory limit of around seven chunks. Miller was not writing about teams. The cognitive limit he found on how many things we can juggle at once maps cleanly onto how many people we can coordinate without losing track of where everyone is.
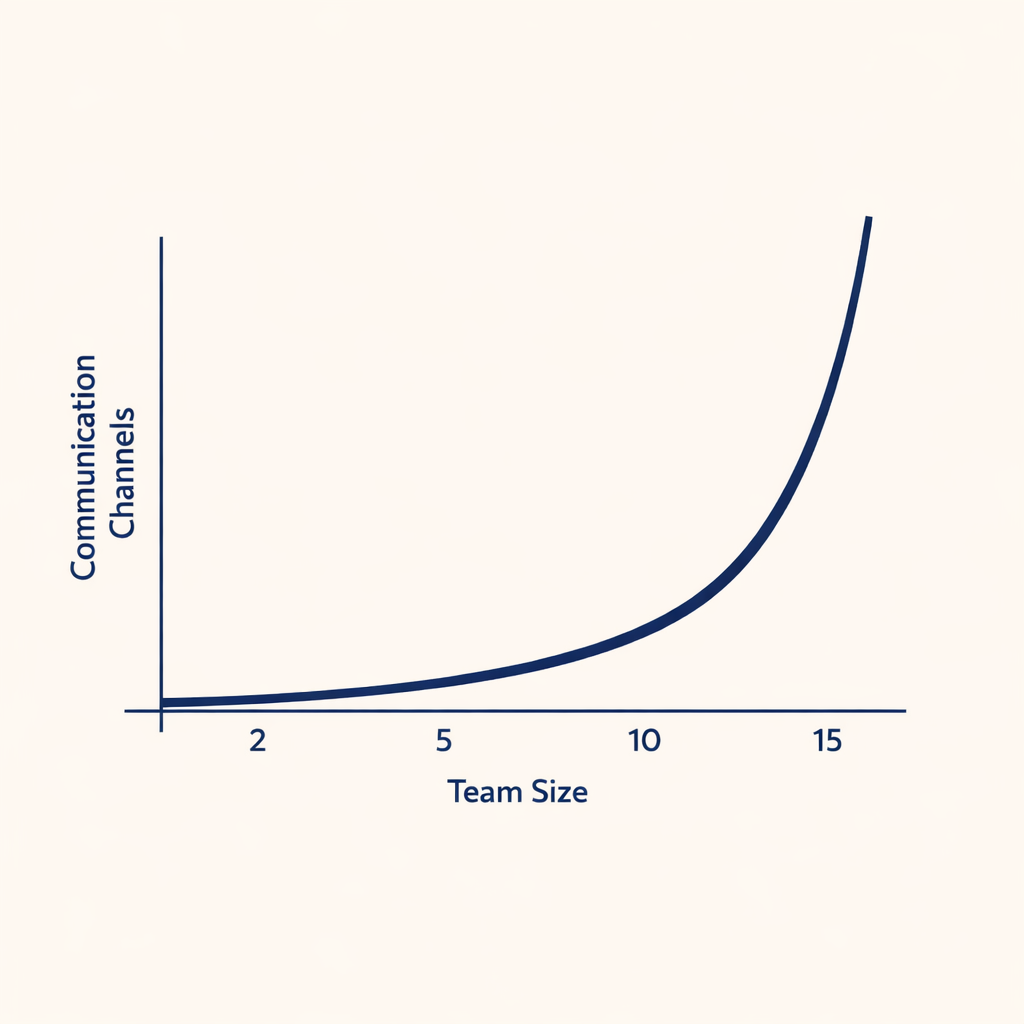
Fred Brooks, in his 1975 book The Mythical Man-Month, observed that adding people to a late software project makes it later, because every new person increases the number of pairwise communication channels by roughly n(n–1)/2. Seven people means 21 channels. Ten means 45. Fifteen means 105. The coordination tax is quadratic, and it surfaces as “mysterious” slowdowns at exactly the team sizes where the math stops being manageable.
W. L. Gore & Associates, the Gore-Tex company, built Dunbar’s number directly into its real-estate strategy. Founder Bill Gore had a rule: every time a building exceeded 150 employees, they built another building. He was running Dunbar’s ceiling inside his facility planning decades before Dunbar had published the paper.
The Ringelmann effect, documented in 1913 and one of the oldest findings in social psychology, is the same story in a different register: as group size grows, the effort each individual contributes goes down. People pull harder on a rope when there are fewer of them holding it. Max Ringelmann measured it with actual rope-pulling experiments, and the finding has been replicated many times since in workplace and sports settings.
The two-pizza team — Bezos’s practical statement of the cognitive sub-layer.
The role change: the first-line manager span is a cognitive limit, not a cost line
A first-line manager’s direct-report span is not a matter of preference for most cognitive work. It sits around 5 to 7. Push it to 10 and managers stop coaching and start triaging. Push it to 15 and the role has reverted to being an individual contributor with a different title. Organizations that scale cleanly keep that first layer tight even when the spreadsheet says it is expensive — because the spreadsheet is not pricing the coordination tax that a wider span produces downstream.
Coordination overhead grows quadratically with team size.
The org change: 50 and 150 are hard boundaries
The sub-team that actually owns a piece of work should be closer to 5 than to 10. Not because small teams are faster in principle, but because the communication-overhead curve gets steep fast after 7. Bezos was right about this, and almost every high-performing team of any reasonable size runs its real work through an informal group of four or five — regardless of what the reporting structure says on the org chart.
When a function crosses 50 people, it needs an operational substructure. Tribes, chapters, pods, whatever the label — or the Dunbar sympathy layer breaks. When the people in a team stop knowing each other well enough that a death in someone’s family would visibly register with everyone, culture starts dying quietly. By the time anyone notices, six months have usually been lost.
When an organization crosses 150, it runs two cultures whether the leadership admits it or not. The question is only whether the split is designed deliberately or happens by default. Organizations that handle the ceiling well accept it and build deliberate boundaries. Organizations that handle it poorly spend years pretending 400 people are “all one team.”
Cross 150 and you either build deliberate substructure or get default fragmentation.
The strategic consequence: org design is surrender, not construction
Good organizational design is mostly a process of surrender. The cognitive architecture of the humans running the teams picks team sizes for you, and the only real choice is whether to build the org chart around what actually works or to fight it and pay the tax. Every commercial organization that has tried to force a bigger number — a 12-person manager span, a 30-person “small team,” a 300-person “family culture” — has either quietly subdivided itself into groups that look suspiciously like the Dunbar numbers, or lost the thing that made it work.
AI augmentation does not move the cognitive ceiling. It moves the throughput below the ceiling. An IC managing four AI agents is still operating inside a span of four. A manager coordinating seven sub-teams of augmented ICs is still operating inside a Dunbar-5 layer. The numbers that governed organizational design before agents are the numbers that will govern it after.
Small intimate teams stay where the work actually gets done.
So what boards should do
Boards should design operating models around the Dunbar layers and treat AI-augmented throughput as a multiplier on what each cognitive unit can do — not as a license to stretch the unit past its ceiling. The specific actions sit at four layers: first-line spans at 5 to 7 even under headcount pressure; sub-team ownership at 5; operational substructure at 50; deliberate cultural boundaries at 150. These are not target numbers. They are discovered numbers. Every other structure is an argument with biology, and biology does not negotiate.
The Roman legions did not know about neocortex ratios. The Marines do not design their fireteams around anthropology papers. Jeff Bezos did not cite Dunbar when he ordered the pizzas. All three converged on the same numbers because the numbers are a property of the animal doing the work, not the work itself. The job of an organizational designer is to notice this — and then get out of the way.
References
Dunbar, R. I. M. (1992). “Neocortex size as a constraint on group size in primates.” Journal of Human Evolution.
Dunbar, R. I. M. (2010). How Many Friends Does One Person Need? Harvard University Press.
Miller, G. A. (1956). “The Magical Number Seven, Plus or Minus Two.” Psychological Review.
Brooks, F. P. (1975). The Mythical Man-Month: Essays on Software Engineering.
Hackman, J. R. (2002). Leading Teams: Setting the Stage for Great Performances. Harvard Business School Press.
Ringelmann, M. (1913). Early social-loafing experiments, Annales de l’Institut National Agronomique.
Gladwell, M. (2000). The Tipping Point. Popularised Gore’s rule of 150 for the management audience.
The Scrum Guide — current recommended team size: 3 to 9 members.
Challenger, Gray & Christmas reported in late March 2026 that U.S. employers announced 217,362 job cuts in Q1 — the lowest Q1 total since 2022. Within that aggregate, technology-sector cuts ran at 52,050, up 40% versus Q1 2025. In March specifically, AI was cited as the rationale for 15,341 cuts — 25% of the month’s total — making it the leading single reason for U.S. layoffs for the first time on the Challenger record. Major contributors to the technology figure: Dell’s annual filing-disclosed restructuring, Oracle’s March layoffs, and Meta’s Reality Labs reduction.
What it means
The aggregate-down, tech-up, AI-leading combination is not three separate stories. It is one story told from three angles. The aggregate number is down because the broad U.S. economy is operating with reasonable employment; sector-by-sector cuts in legacy industries are running below historical norms. The technology number is up because the sector is going through a structural reallocation — capital is shifting from headcount-led growth to compute-led growth, and the cost base of large software companies is being explicitly redesigned around that shift. AI is the leading cited reason because it is the strategic narrative that justifies the redesign to investors, customers, and remaining employees.
The implication for the rest of 2026: technology-sector hiring patterns will continue to diverge from the broader economy. Companies will hire aggressively for ML, infrastructure, agent operations, and applied research while shrinking headcount in functions that AI is augmenting or displacing. Net headcount may decline, but the per-employee compute and capability budget rises sharply. That changes what “growth” looks like in the financial reporting of the sector.
Andreas’s view
My read on this: the Q1 numbers are not a downturn signal — they are a transformation signal masquerading as cost discipline. Tech companies are not in distress. They are restructuring around the assumption that a smaller, AI-augmented workforce produces equal or greater output at a different cost basis. Some of those bets will be right; some will be the Block experience at smaller scale, where the rehire follows the cut by six to twelve weeks. The Q2 and Q3 numbers will tell us how clean the underlying productivity gain actually is.
I don’t think the AI-as-cited-reason metric stabilizes here. It rises through 2026. Once the framing carries an investor-relations multiple — which Block demonstrated — the disclosure pattern shifts in its direction across the sector. By year-end, AI-cited cuts will likely cross 30% of monthly U.S. totals, and that will look more like a permanent baseline than a peak.
The way I see it: the Challenger headlines document neither a labor crisis nor a productivity victory. They are capturing a sector-wide capital reallocation with a coherent strategic logic and uneven execution quality. The more interesting question to me is which side of that reallocation any given business is on — and whether its cost base reflects the structure it has today or the structure it intends to have in 18 months.
Three things I’m watching
Three things I’m watching as this plays out:
I’ll be watching whether companies are tracking the technology-sector comparison for their own organization: revenue, headcount, and per-employee compute spend versus the closest five public-market peers. That gap is where structural exposure shows up first.
I’ll be watching whether organizations hold a meaningful distinction in their communications between AI-driven productivity reductions — workflow-modeled, with measurable output — and broader restructuring justified by other factors. The market may not differentiate; but the ones with rigorous operations will.
I’ll be watching Q3 unit economics against any Q1 workforce action. The reduction is on the books in Q1; whether the underlying productivity thesis holds shows up in Q3 output measures, not headcount.
Related signal: Block’s 4,000-person cut in late February established the public investor-reaction benchmark for AI-narrated reductions; the Q1 pattern reflects companies responding to that signal.
Through the week of February 16–22, 2026, the AI-cited layoff story moved from edge case to mainstream framing. AI was cited as the rationale for 4,680 February job cuts in the U.S. — roughly 10% of the month’s total. Baker McKenzie announced 600–1,000 layoffs (up to 10% of global headcount) framed as a pivot to AI-augmented service delivery. Dow disclosed 4,500 cuts in January with explicit AI-strategy framing. A Harvard Business Review piece in the same window argued that companies are laying off based on AI’s potential, not its measured performance. An Oxford Economics report from January concluded that many AI-cited layoffs were the consequence of past overhiring, not present AI productivity.
What it means
Two things are happening at once. First, AI productivity is real for specific workflows and starting to show up in unit-cost reductions. Second, “AI” is becoming the public-facing rationale for cost actions that boards and CEOs have wanted to take for other reasons — overhiring during 2021–2022, deteriorating margins in slower-growth segments, restructuring to a target operating model that was already in motion. The two stories overlap, and the public communication does not distinguish between them.
For employees, the framing matters because “we are restructuring” and “AI is replacing your role” carry different signals about whether the function comes back. For investors, it matters because the market is pricing AI-cited cost reductions as durable while restructuring-cited cost reductions are typically priced as one-off. CEOs who choose the AI framing get a multiple uplift. That incentive structure tells you why the framing is becoming dominant.
Andreas’s view
My read on this: the next 12 months will see a steady drift toward AI-as-explanation in layoff communications, regardless of whether AI is the underlying driver. The reason is not deception — it is signaling. CEOs need a forward-looking story that the cost base will stay reduced, and “AI productivity” is a cleaner story than “we hired too aggressively in 2022.” The public record will eventually reconcile this; quarterly earnings will reveal which companies actually shipped the productivity gain and which simply downsized.
I don’t think the workforce numbers are yet the right metric to watch. The right metric is the ratio of revenue per employee in the months after the cut. If revenue per employee climbs durably, the AI framing was substantively correct. If it plateaus or reverses while operational quality declines, the framing was a positioning move and the company will be hiring back inside 18 months — at higher cost and lower morale.
The way I see it: when a CEO presents an AI-cited workforce action, the productivity model behind it should be specific enough to name which workflows, which output measures, which time horizon, and which control group. Where those answers are vague, the action is restructuring with AI vocabulary. That is not necessarily wrong, but the distinction matters — and I think it matters most at the board level, where the conversation should reflect what is actually driving the decision.
Three things I’m watching
Three things I’m watching as this plays out:
I’ll be watching whether companies maintain a clear internal distinction between AI-driven productivity actions (with a workflow-level model behind them) and AI-framed restructuring actions (justified by other reasons). Both can be valid; conflating them confuses execution, and the ones that keep the distinction clean are more likely to deliver what they promised.
The companies that track revenue per employee monthly for the 12 months following any AI-cited workforce reduction will have the clearest view of whether the productivity gain actually materialized — and I’ll be looking at that number as the most honest signal in the public record.
I’ll be watching how specific companies get in their external communication around AI-related workforce changes. Vague “AI is making us more productive” framing tends to erode credibility internally faster than a precise statement of which work has been automated and which has been redesigned — and over the next year, that credibility gap will start showing up in retention and hiring data.
Through the week of February 9–15, 2026, the enterprise AI deployment story sharpened around a paradox: 95% of generative AI pilots still fail to reach production, yet 42% of enterprises now run agentic AI in production and 72% have agentic systems live in production or pilot. Microsoft’s February enterprise update reframed Copilot from “assistant” to “governance-first agent” capable of completing entire workflows. Oracle introduced Fusion Agentic Applications for finance, supply chain, and HR. OutSystems research released the same week reported that 94% of enterprises adopting agentic AI now flag agent sprawl as a primary concern.
What it means
The two statistics are not in conflict. They describe two different populations of organizations. The 95%-pilot-failure number describes how the average enterprise treats generative AI: a proof-of-concept budget, a small team, and a handoff to operations that never happens. The 42%-in-production number describes a smaller cohort that has done the operational work — governance, identity, runtime monitoring, rollback procedures, and explicit ownership of the agent fleet. The gap between the two cohorts is not technical. It is procedural.
Microsoft’s “governance-first agent” framing acknowledges this directly. The next phase of enterprise AI is not better models. It is the operating discipline around models — who deploys them, who owns them when they misbehave, who pays for the inference, and how the organization rolls back a bad agent without disrupting downstream work. That is a CIO problem, not a CTO problem.
Andreas’s view
My read on this: the production cohort is pulling away from the pilot cohort, and the gap is widening every quarter. The companies in production are accumulating an operational learning curve — what governance looks like, how to staff agent operations, how to track agent behavior in production, how to compose agents into workflows without losing accountability. The companies still iterating on pilots are accumulating learnings about prompts and demos. Those are different skill sets and they compound at different rates.
I don’t think the next 12 months reward the companies that pick the best model. They reward the companies that figured out how to operate any reasonable model at production scale, with controls, with monitoring, and with an explicit chain of accountability when an agent does the wrong thing. Agent sprawl is the leading indicator that the operations layer is missing — when 94% of practitioners flag it as a top concern, the conversation has moved past whether agents work and onto whether they are manageable.
The way I see it: the clearest signal a board can get on where an organization actually stands is whether the CIO can produce a production agent inventory — by name, by owner, by usage volume, by incident count. If the question produces a list, the organization is in the production cohort. If it produces “we are still piloting,” it is in the failure cohort, and the strategic gap to peers will be visible in operating costs by mid-2027.
Three things I’m watching
Three things I’m watching:
I’ll be watching whether companies can produce a named, owned, monitored agent inventory with rollback procedures on demand — that capability is the clearest proxy I have for whether a real agent operating model exists or not.
The organizations that interest me are the ones shifting pilot evaluation from “did the demo work” to “did the agent ship to production with controls in place” — and backing that shift by defunding pilots that stay in demo mode past a fixed time-box.
The question I’d be asking myself is whether a dedicated agent-operations lead — with explicit authority over the production fleet and seniority equivalent to the head of enterprise systems — is in place. Without single ownership, sprawl is the default outcome, and I expect that to show up clearly in incident and cost data over the next several quarters.
Related signal: Anthropic’s Model Context Protocol crossed 97 million installs in March — production-grade agent infrastructure is consolidating around a small number of standards, which lowers the operational excuse not to ship.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.